
大语言模型(Large Language Model, LLM)无疑是当前最为引人注目的技术之一,这些模型以其惊人的能力在自然语言处理(NLP)任务中展现了卓越的表现。那么,大语言模型的核心原理是什么?它们是如何实现高效的自然语言理解与生成的?本文将为你详细解析大语言模型的工作机制。
1. 大语言模型的基本概念
大语言模型是通过深度学习技术构建的人工智能系统,其主要任务是理解和生成自然语言文本。这些模型通常由数十亿到数万亿个参数组成,能够学习并模拟语言的复杂结构和规律。
大语言模型的核心原理包括以下几个方面:
- 神经网络架构:大语言模型通常基于变换器(Transformer)架构,这种架构通过自注意力机制(Self-Attention)处理序列数据,能够捕捉文本中的长期依赖关系和上下文信息
- 预训练和微调:模型首先通过无监督学习进行预训练,学习语言的基本特征,然后通过有监督学习在特定任务上进行微调,以提高模型在特定应用场景中的性能
- 参数调整:在训练过程中,模型的参数通过反向传播算法进行调整,以最小化预测与实际结果之间的误差,模型逐渐学习到语言的规律和模式
这些原理共同作用,使得大语言模型能够理解和生成自然语言文本。
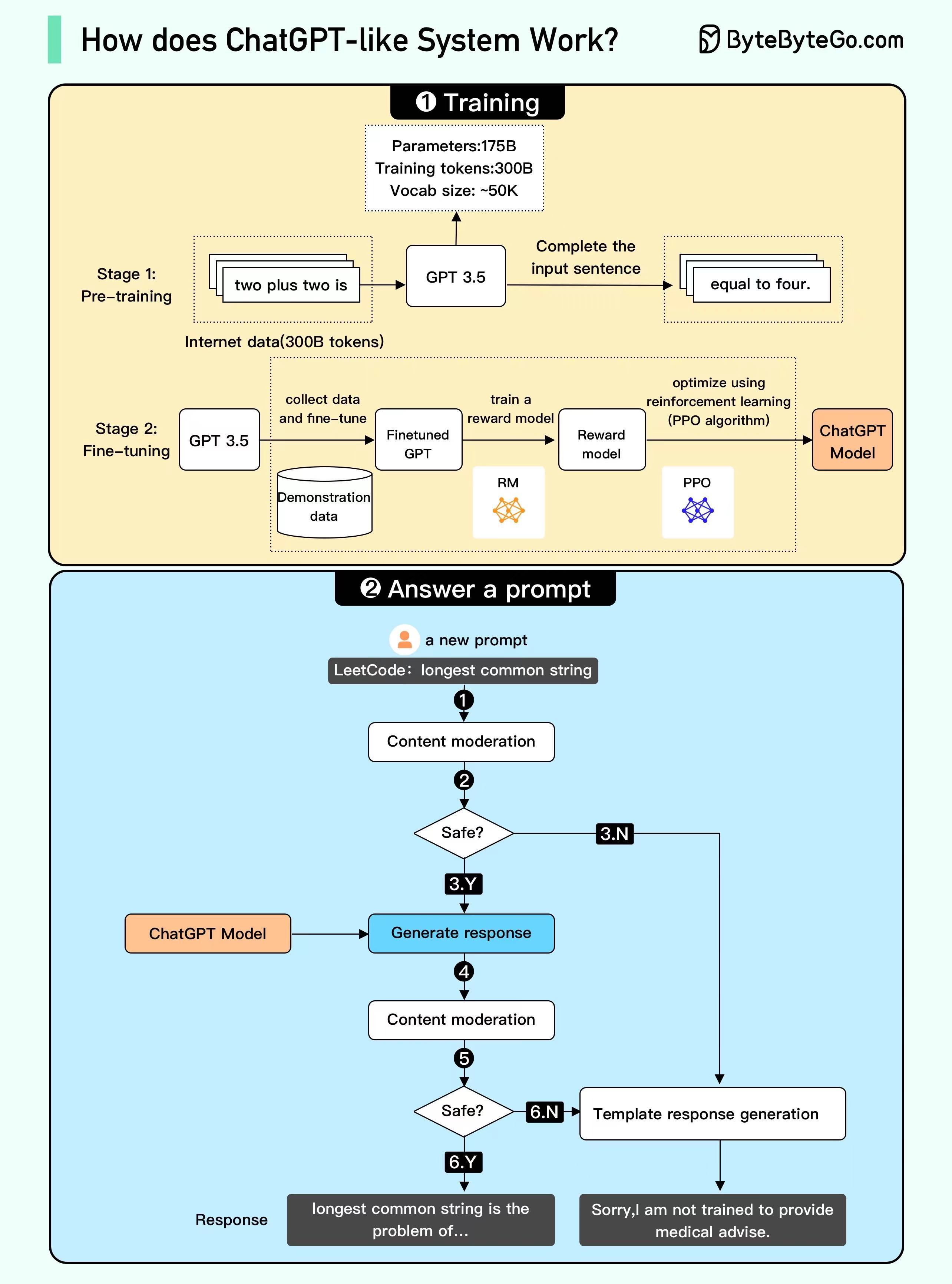
2. 变换器架构的核心原理
变换器(Transformer)架构是大语言模型的基础,它的核心组件包括自注意力机制和前馈神经网络。
- 自注意力机制:自注意力机制使得模型能够关注输入序列中的所有位置,并根据上下文加权输入的不同部分。这种机制允许模型在处理每个词时,同时考虑到其他所有词的影响,从而捕捉长距离依赖关系
- 前馈神经网络:变换器中的每个层包含一个前馈神经网络,用于对每个位置的表示进行非线性变换。前馈网络通过多层感知机(MLP)对输入进行复杂的非线性映射
- 位置编码:由于变换器本身不具备处理序列顺序的能力,模型使用位置编码(Position Encoding)来引入序列中词的位置信息,从而保持词序列的顺序信息
变换器架构通过这些机制,实现了高效的序列建模和语言处理能力。
3. 预训练与微调的过程
大语言模型的训练过程分为预训练和微调两个阶段:
- 预训练:在预训练阶段,模型通过无监督学习对大规模的文本数据进行训练。这一步骤旨在让模型学习语言的基本特征和规律,通常使用的任务包括语言建模(预测下一个词)、遮蔽语言建模(填补缺失的词)等
- 微调:在微调阶段,模型在特定任务的数据上进行有监督学习,以适应特定的应用场景。这一步骤通过调整模型参数,使得模型在特定任务中表现更例如问答系统、文本分类等
通过这种训练过程,大语言模型能够在广泛的语言任务中表现优异。
4. 应用中的自然语言理解与生成
大语言模型在实际应用中主要通过以下方式实现自然语言理解与生成:
- 自然语言理解:模型通过分析输入的文本,提取其中的语义信息。这包括识别文本中的实体、理解句子的意图、推断上下文等
- 自然语言生成:模型基于上下文生成相关的自然语言文本。这包括生成回答、撰写文章、创作对话等,生成的文本通常流畅自然,并符合上下文的要求
这些能力使得大语言模型在各种自然语言处理任务中发挥了重要作用,包括智能客服、内容生成、机器翻译等。
5. 大语言模型的挑战与发展方向
尽管大语言模型在语言处理领域表现出色,但仍面临一些挑战:
- 计算资源:训练大语言模型需要大量的计算资源和能源,这对计算基础设施和环境带来压力
- 算法偏见:模型可能继承训练数据中的偏见,需要通过改进训练数据和算法来解决
- 数据隐私:在处理个人数据时,需要确保用户隐私和数据安全
未来的发展方向包括提升模型的效率、减少资源消耗、解决算法偏见问题,并推动模型在更多应用场景中的实际应用。
大语言模型通过其复杂的神经网络架构和训练过程,实现了自然语言的深度理解与生成。随着技术的不断进步,这些模型将继续推动自然语言处理技术的发展,并在更多领域发挥重要作用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


